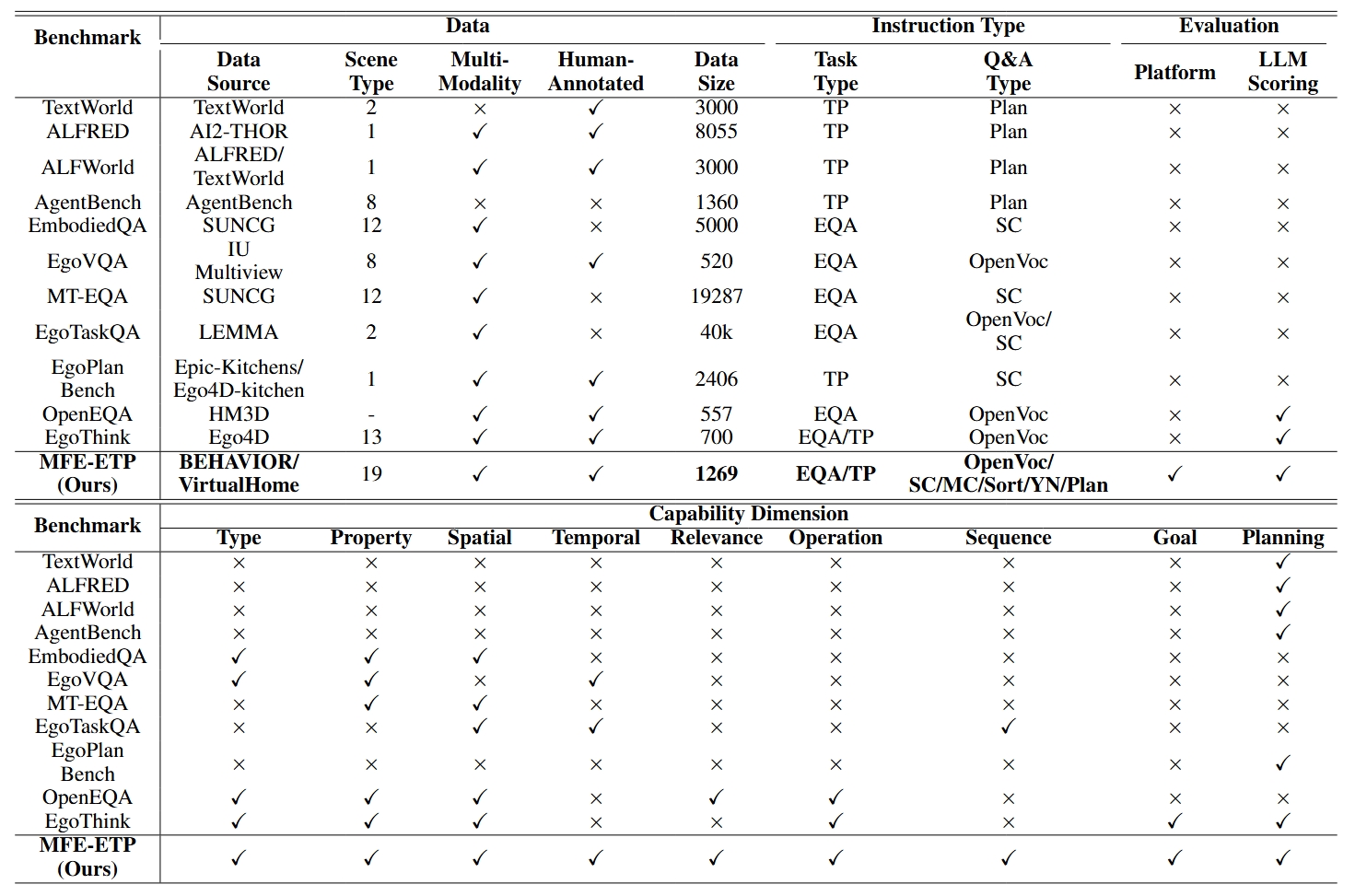
Benchmarks Comparison
Comparison of various benchmarks. EQA: Embodied Question Answering, TP: Task Planning, SC/MC/Sort/YN/Plan indicate Single-Choice, Multi-Choice, Sorting, Yes/No, and Planning.
In recent years, Multi-modal Foundation Models (MFMs) and Embodied Artificial Intelligence (EAI) have been advancing side by side at an unprecedented pace. The integration of the two has garnered significant attention from the AI research community. In this work, we attempt to provide an in-depth and comprehensive evaluation of the performance of MFM s on embodied task planning, aiming to shed light on their capabilities and limitations in this domain. To this end, based on the characteristics of embodied task planning, we first develop a systematic evaluation framework, which encapsulates four crucial capabilities of MFMs: object understanding, spatio-temporal perception, task understanding, and embodied reasoning. Following this, we propose a new benchmark, named MFE-ETP, characterized its complex and variable task scenarios, typical yet diverse task types, task instances of varying difficulties, and rich test case types ranging from multiple embodied question answering to embodied task reasoning. Finally, we offer a simple and easy-to-use automatic evaluation platform that enables the automated testing of multiple MFMs on the proposed benchmark. Using the benchmark and evaluation platform, we evaluated several state-of-the-art MFMs and found that they significantly lag behind human-level performance. The MFE-ETP is a high-quality, large-scale, and challenging benchmark relevant to real-world tasks.
Comparison of various benchmarks. EQA: Embodied Question Answering, TP: Task Planning, SC/MC/Sort/YN/Plan indicate Single-Choice, Multi-Choice, Sorting, Yes/No, and Planning.
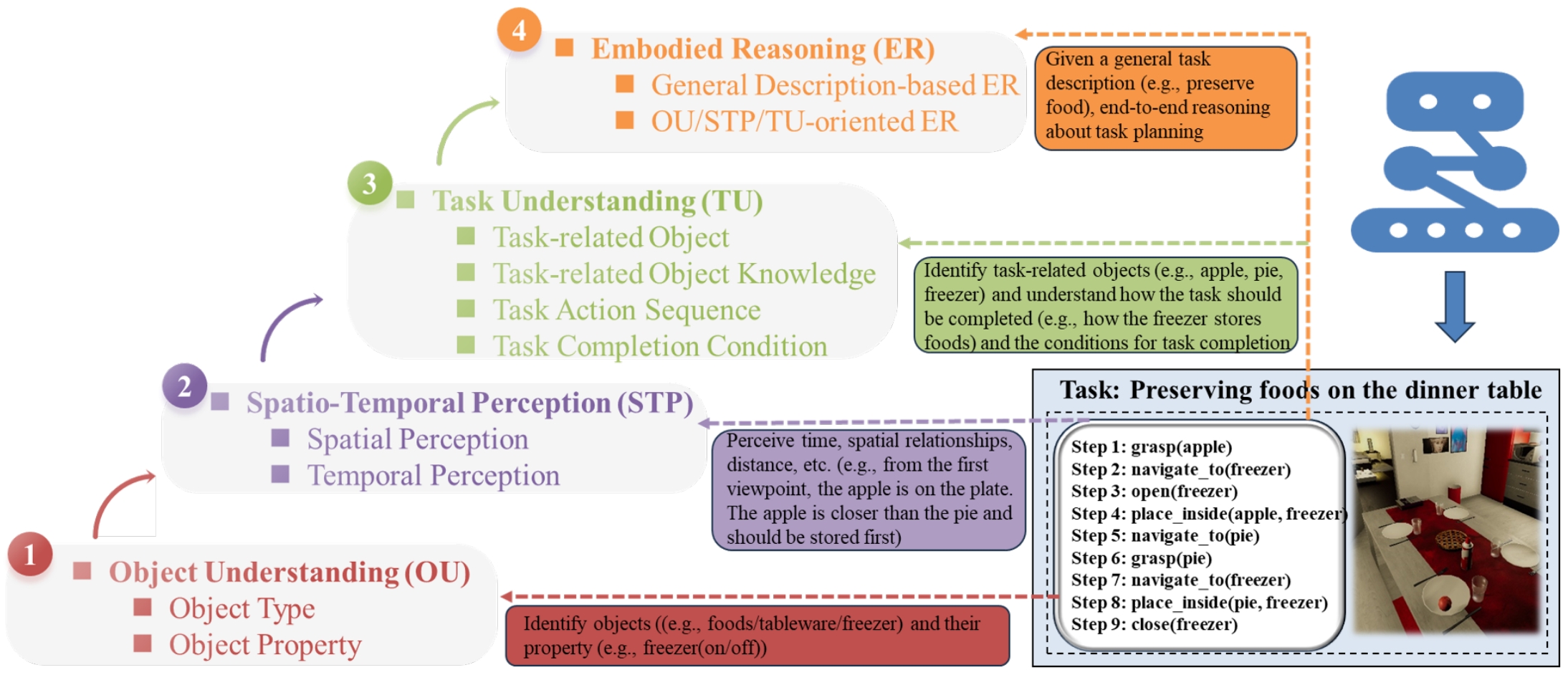
We proposed an evaluation framework designed for embodied task planning, which consists of four levels of crucial capabilities, namely object understanding, spatio-temporal perception, task understanding, and embodied reasoning. Each capability dimension is further decomposed into several sub-aspects.
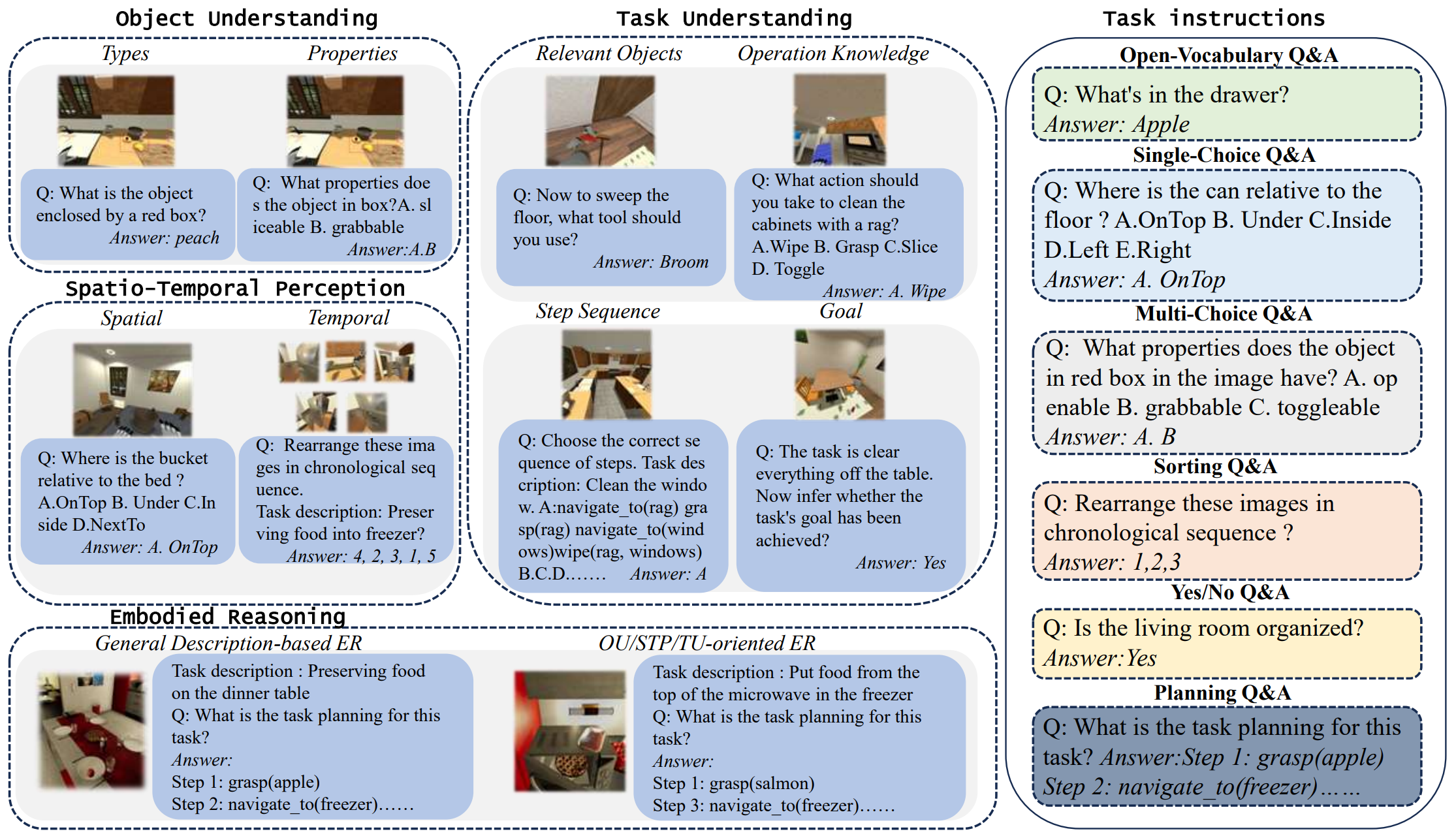
We display example question-and-answer pairs of our benchmark on different capability dimensions and the six types of task instructions used. In addition, we have carefully designed a total of 156 task descriptions for different capability dimensions and combined them with specific task instructions to generate more diverse task text prompts.
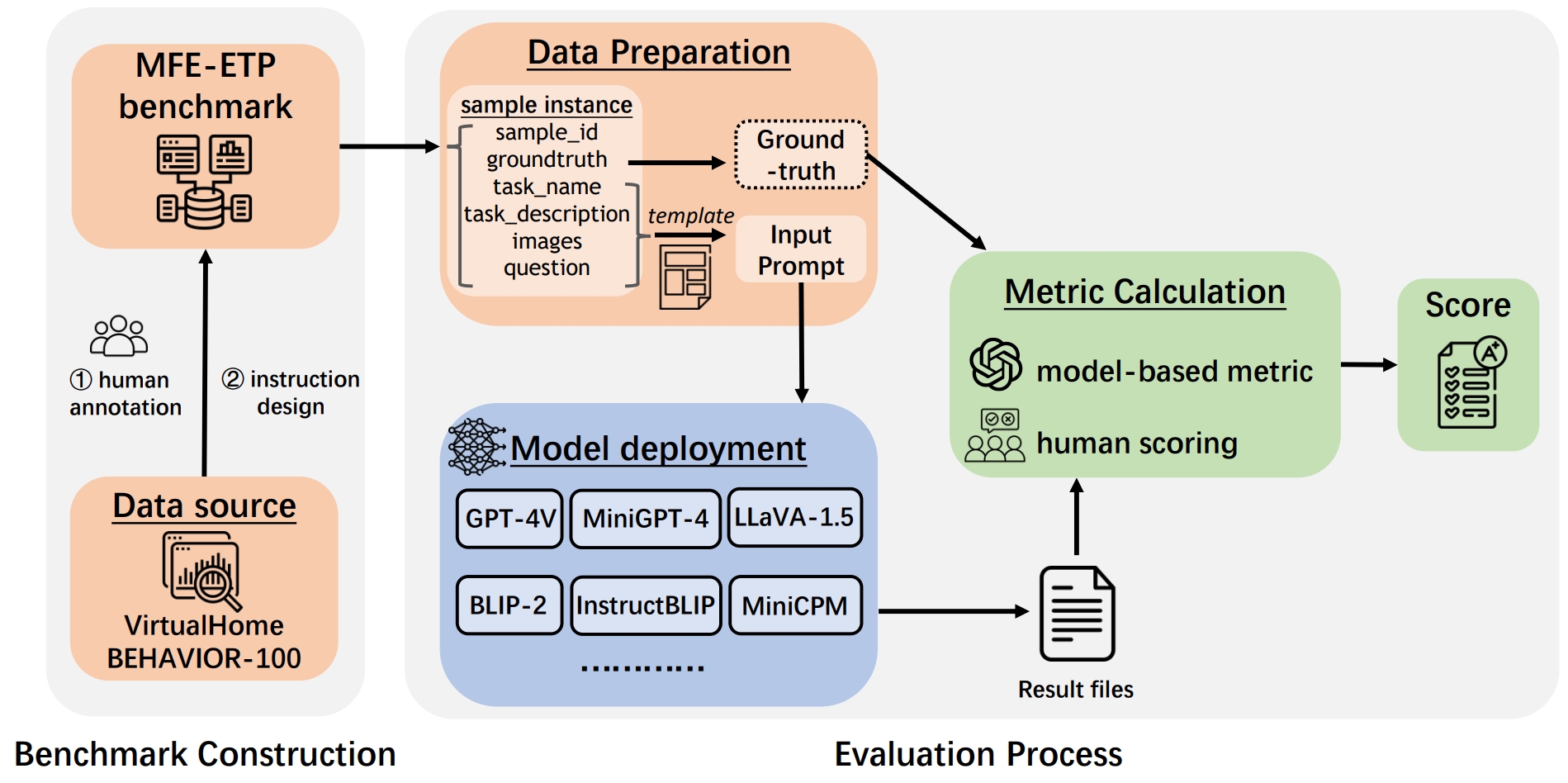
Our evaluation workflow involves benchmark construction, data preparation, model deployment, and metric calculation to derive the final score.
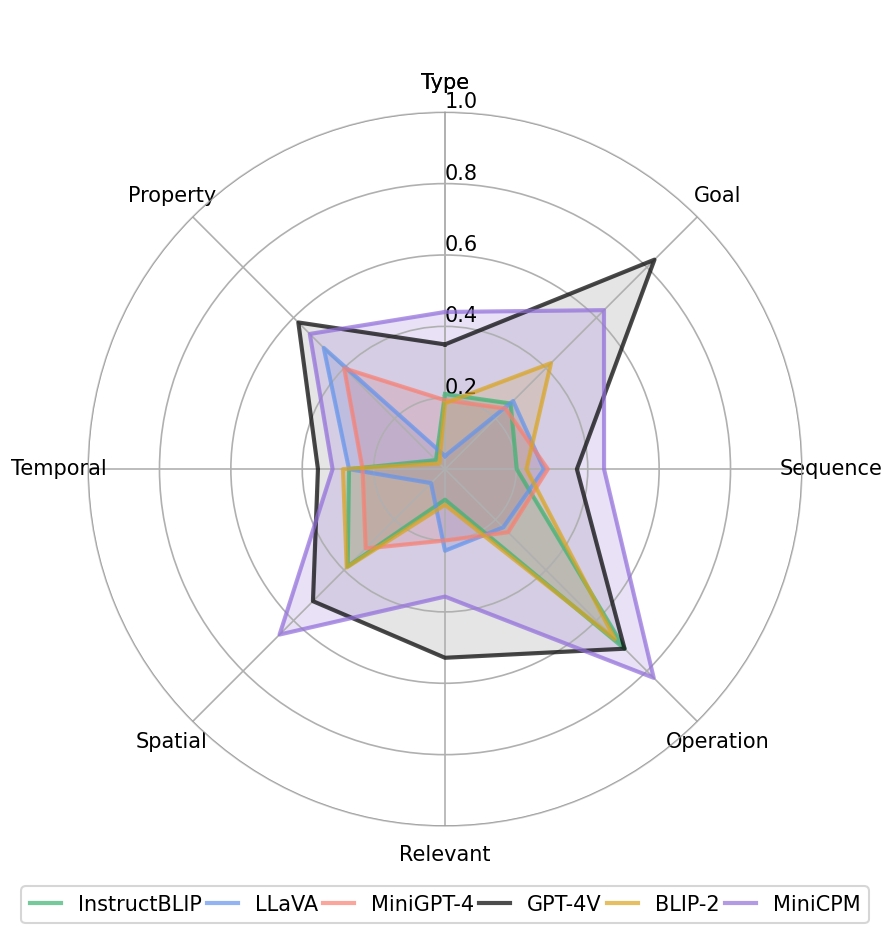
We evaluate the performance of GPT-4V and five other open-source MFMs, namely BLIP-2, MiniGPT-4, InstructBLIP, LLaVA-1.5, and MiniCPM. We can draw the following general conclusions: 1. GPT4V and MiniCPM significantly outperform the other four MFMs, with a performance improvement of over 100\% compared to the worst-performing LLaVA-1.5. 2. MiniCPM performs close to GPT-4V and is better than the other open-source MFMs in all aspects. 3. Compared with higher-level and more abstract task understanding capabilities, MFMs generally perform worse in low-level perception capabilities such as object understanding and spatiotemporal perception.

@misc{zhang2024mfeetpcomprehensiveevaluationbenchmark,
title={MFE-ETP: A Comprehensive Evaluation Benchmark for Multi-modal Foundation Models on Embodied Task Planning},
author={Min Zhang and Jianye Hao and Xian Fu and Peilong Han and Hao Zhang and Lei Shi and Hongyao Tang and Yan Zheng},
year={2024},
eprint={2407.05047},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2407.05047},
}